7. Clkctrs#
7.1. Required files#
7.2. Introduction#
This tutorial demonstrates the Clkctr (clock counter) feature of SpaceStudio, used to track time with uniform methods over software and hardware.
This tutorial shows how to use Clkctrs to monitor software and hardware execution of an image processing application, allowing an informed architecture exploration.
7.3. Application#
The tutorial is based on an edge detection application using the Sobel filter, which performs two 3x3 convolutions [1]. The application takes a grayscale image as input and applies the filter to the entire image for a fixed number of times, allowing to compute an average execution time of the algorithm. The resulting output image can be obtained after execution, Figure 7.1 shows an example of the input and output images.

Figure 7.1 Input image (left) and output image (right) of an application execution#
The input image can be seen or modified in the imports/images directory inside the SpaceStudio project location, and must be named image_in.pgm. If a new image is used, its dimensions must be set inside application_definitions.h. The image width must be a multiple of four times the slice count.
The application uses the binary PGM image file format (P5) [2]. These images can be viewed or converted to other formats using GIMP or the ImageMagick command-line tool.
7.3.1. Application architecture#
he tutorial project runs on a Zynq-7000 SoC and contains two application components :
Controller: A single instance of this module runs in software on the SoC CPU. It reads and verifies the input image, writes the data to the board’s DDR memory, and triggers the Sobel instances for a configurable number of iterations. Once processing is complete, it formats and outputs the result image. The controller also measures the average execution time of the iterations using the
std::chronoAPI.Sobel: Runs in hardware and applies the Sobel filter on a slice of the image. It reads the data and writes its output in the DDR memory. Multiple instances of this module can run in parallel, each processing a separate slice. The image is automatically sliced and distributed based on the number of instantiated Sobel modules.
Figure 7.2 shows a diagram of the application architecture.
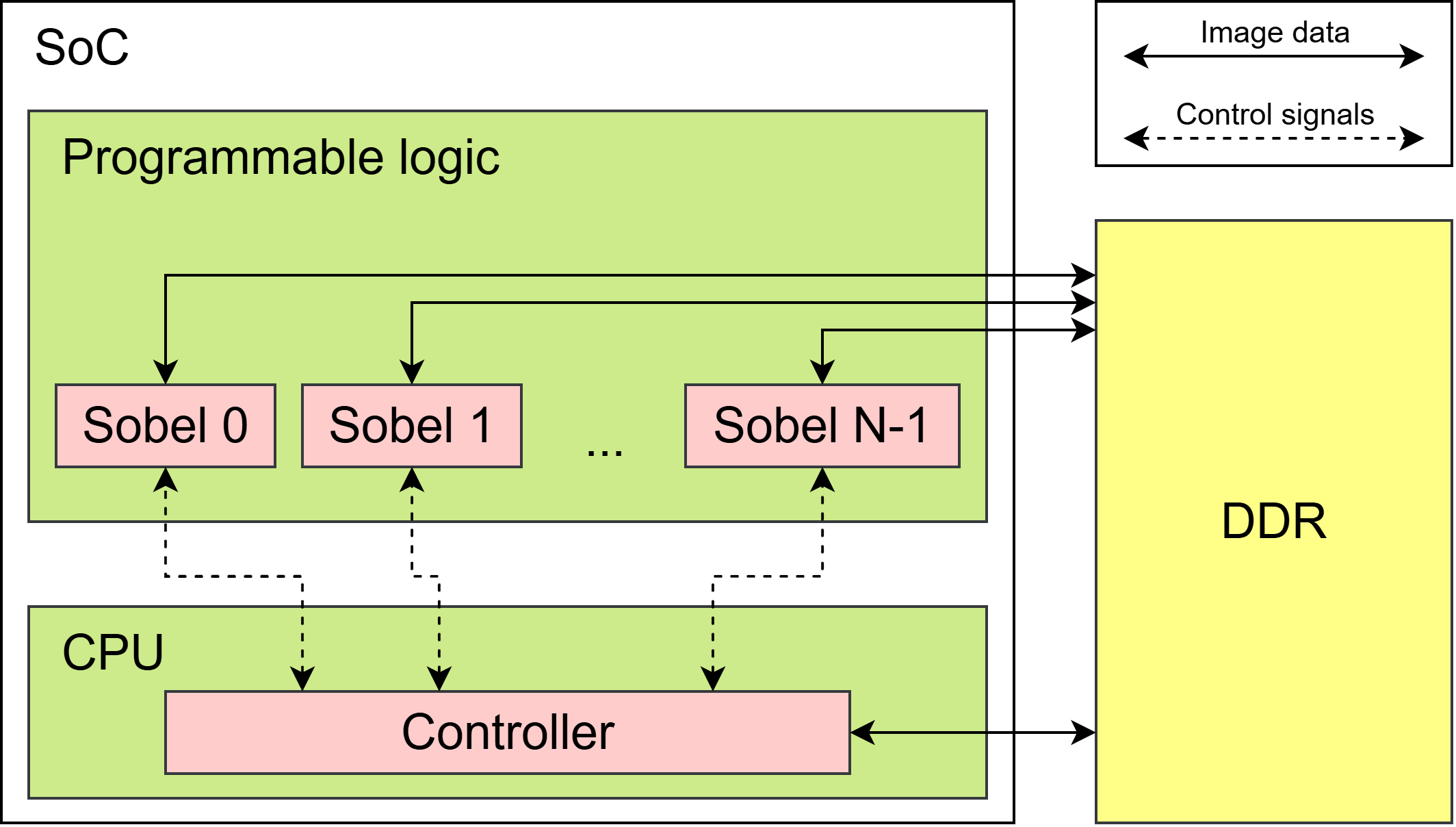
Figure 7.2 Diagram of the application architecture#
Note
The memory architecture of the Sobel module is optimized to maximize throughput. Details of the different optimizations are outside of the scope of this tutorial, refer to [3] for more details.
7.3.2. Time monitoring needs#
Experimental results show that adding Sobel instances accelerates the execution linearly with a low number of slices, but execution time reaches a limit at higher counts. Additional Sobel instances provide negligible acceleration beyond that point.
The execution of a Sobel module is mostly divided between data transfer and processing. Monitoring the time spent in each part is needed to identify the one causing the bottleneck, and make informed decisions about the final architecture. However, the standard std::chrono API is only available for software modules, with no equivalent abstraction for hardware execution. This limitation motivated the development of SpaceStudio’s Chrono API, specifically the Clkctrs, to enable uniform timing measurements across software and hardware components.
Note
A Zynq-7000 SoC can fit up to 10 Sobel instances. Larger platforms can be used to explore the architecture further.
7.4. Clkctrs#
7.4.1. Concept#
The Clkctr API allows a module to get the current time efficiently and uniformly whether in software or in HLS generated hardware. Under the hood, the API generates a hardware counter IP if it’s called from a hardware module. When called from software, it uses the OS time similarly to how the std::chrono API works.
The Clkctr API uses the concept of clock domains and extends it to software. It can either be a real hardware clock domain or an operating system, each OS of an application is considered a separate clock domain. When using a Clkctr, the user must specify the target clock domain, as each domain has its own internal time.
7.4.2. Use cases#
Currently, the API supports three use cases:
A software module gets the time of a software module, itself or a different one.
A software module gets the time of a hardware module.
A hardware module gets its own time.
7.4.3. Usage#
Access to the Clkctr API is via the SPACE_CLKCTR_HANDLE macro:
SPACE_CLKCTR_HANDLE(calling_module, calling_idx, calling_thread,
SPACE_ID(target_module, target_idx), clk_variable);
Where :
module,calling_idxandthreadare the module name, index and thread name of the module thread asking for the clock.target_moduleandtarget_idxare the module name and index of the module instance whose clock domain is tracked.clk_variableis the name of the variable storing the clock.
With the clock variable defined, a module can get the current time point with the .now() method. Using the auto keyword avoids dealing with complex type definitions.
// The thread 'thread' of the 'producer' of index 'INDEX' wants a 'consclk' variable
// that refers is on domain the 'consumer' of index 'INDEX' .
SPACE_CLKCTR_HANDLE(producer, INDEX, thread, SPACE_ID(consumer, INDEX), consclk);
// ...
const auto start = consclk.now();
do_something();
const auto end = consclk.now();
Time points can be subtracted to compute an elapsed time, and converted to usable values using one of two methods :
.to_sec<type>()returns the number of seconds elapsed in the specified type. It is currently only available for software clocks..jiffies()returns the number of ticks elapsed. In hardware, this corresponds to the number of clock cycles and can be converted to time units using the module clock frequency.
#if MAPPING = SW_MAPPING
float elapsed_sec = (end - start).to_sec<float>(); //Only available to software
#else //HW_MAPPING
uint32_t hw_frequency = 100e6;
uint64_t elapsed_ticks = (end - start).jiffies();
float elapsed_sec = static_cast<float>(elapsed_ticks) /
static_cast<float>(hw_frequency);
#endif
Note
Documentation for SpaceStudio’s chrono API can be found in the Clkctrs section.
7.5. Manipulations#
The following manipulations show the three Clkctrs use cases applied to the Sobel Operator application, and how to get time profiling of the hardware Sobel modules execution.
7.5.1. Create a new solution#
Start from the provided SpaceStudio project and create a new solution based on the existing one. Remove the lines used to track time in controller.cpp (i.e., the std::chrono include and all lines referring to the chrono API or the execution_time variable).
7.5.2. Include Spacestudio’s Chrono API#
In controller.cpp and sobel.cpp, add:
#include "space_chrono.h"
7.5.3. Use case 1: Software module reads a software clock#
At the start of the thread method inside controller.cpp, declare a software Clkctr tracking the Controller instance :
SPACE_CLKCTR_HANDLE(controller, INDEX, thread,
SPACE_ID(controller, INDEX), controller_clk);
This can be then used to track the time spent waiting for the Sobel instances execution :
double cumul_sw_execution_time = 0;
//…
for (int i = 0; i < NUM_ITERATIONS; i++) {
const auto sobel_start_sw = controller_clk.now();
// Notify sobel modules to start working
//…
// Wait for sobel modules to complete
//…
const auto sobel_end_sw = controller_clk.now();
cumul_sw_execution_time += (sobel_end_sw - sobel_start_sw).to_sec<double>();
}
7.5.4. Use case 2: Software module reads a hardware clock#
Still in controller.cpp, declare a hardware Clkctr tracking the clock domain of the first Sobel instance. As all Sobel instances share the same clock domain, this clock tracks the parallel execution of all hardware instances.
SPACE_CLKCTR_HANDLE(controller, INDEX, thread, SPACE_ID(sobel, 0), sobel_clk);
It can be used in the same way as the software Clkctr from the previous manipulation. In this case the actual clock cycle number is measured with a hardware counter IP :
double cumul_sw_execution_time = 0;
double cumul_hw_execution_time = 0;
//…
for (int i = 0; i < NUM_ITERATIONS; i++) {
const auto sobel_start_sw = controller_clk.now();
const auto sobel_start_hw = sobel_clk.now();
// Notify sobel modules to start working
//…
// Wait for sobel modules to complete
//…
const auto sobel_end_sw = controller_clk.now();
const auto sobel_end_hw = sobel_clk.now();
cumul_sw_execution_time += (sobel_end_sw - sobel_start_sw).to_sec<double>();
cumul_hw_execution_time +=
static_cast<double>((sobel_end_hw - sobel_start_hw).jiffies()) / HW_FREQUENCY;
}
7.5.5. Use case 3: Hardware module reads its own hardware clock#
This is the most useful case for this application. It allows to measure the time of the different execution parts inside the Sobel hardware instances and send them explicitly to the software Controller. At the start of the thread method inside sobel.cpp, declare the Clkctr :
SPACE_CLKCTR_HANDLE(sobel, INDEX, thread, SPACE_ID(sobel, INDEX), clk);
As every Sobel module instance shares the same clock domain, all instances are able to read time from a single hardware counter.
The communication time can now be determined from the duration of all DDR DeviceRead() and DeviceWrite() uses, for example :
uint64_t communication_time = 0;
auto start_communication_time = clk.now();
DeviceWrite(...);
auto end_communication_time = clk.now();
communication_time += (end_communication_time - start_communication_time).jiffies();
And the time of actual computation can be determined in a similar way :
uint64_t computation_time = 0;
//…
// Perform Sobel line per line
for (unsigned int line = 1; line < img_height-1; ++line) {
auto start_computation_time = clk.now();
// Instantiate the window for the first pixel of the line
//…
// Compute the operator for each pixel of the line
//…
auto end_computation_time = clk.now();
computation_time += (end_computation_time - start_computation_time).jiffies();
// Write the output line
//…
// Read the next line
//…
}
Finally, measure the complete execution time seen from the Sobel hardware instance :
uint64_t total_time = 0;
// Wait for the controller notification
ModuleRead(CONTROLLER0_ID, SPACE_BLOCKING);
auto start_total_time = clk.now();
//…
auto end_total_time = clk.now();
total_time += (end_total_time - start_total_time).jiffies();
// Notify controller we are done
ModuleWrite(CONTROLLER0_ID, SPACE_BLOCKING);
These measurements can be transferred explicitly to the controller for formatting and printing. At the end of the sobel.cpp thread, add :
// Send timing data to controller
ModuleWrite(CONTROLLER0_ID, SPACE_BLOCKING, communication_time);
ModuleWrite(CONTROLLER0_ID, SPACE_BLOCKING, computation_time);
ModuleWrite(CONTROLLER0_ID, SPACE_BLOCKING, total_time);
Then inside controller.cpp, declare a new array storing the measurements from all Sobel instances:
double cumul_sobel_clock_data[SOBEL_GROUP_SIZE][3] = {0};
And add code to receive and store the measurements in seconds at the end of Controller’s execution:
uint64_t communication_time; // holds sobel communication time (in clock cycles)
uint64_t computation_time; // holds sobel computation time (in clock cycles)
uint64_t total_time; // holds sobel total execution time (in clock cycles)
// Get Clkctr data measured inside the hardware modules
for (unsigned int index = 0; index < SOBEL_GROUP_SIZE; ++index) {
ModuleRead(SOBEL_GROUP[index], SPACE_BLOCKING, communication_time);
ModuleRead(SOBEL_GROUP[index], SPACE_BLOCKING, computation_time);
ModuleRead(SOBEL_GROUP[index], SPACE_BLOCKING, total_time);
cumul_sobel_clock_data[index][0] += static_cast<double>(communication_time) / HW_FREQUENCY;
cumul_sobel_clock_data[index][1] += static_cast<double>(computation_time) / HW_FREQUENCY;
cumul_sobel_clock_data[index][2] += static_cast<double>(total_time) / HW_FREQUENCY;
}
7.5.6. Add a detailed print#
The print_results() method inside controller.cpp needs an update to output the new measurements:
void controller::print_results(double cumul_sw_time, double cumul_hw_time,
double cumul_sobel_clock_data[SOBEL_GROUP_SIZE][3]) {
const double sw_avg = cumul_sw_time/NUM_ITERATIONS;
const double hw_avg = cumul_hw_time/NUM_ITERATIONS;
printf("\n============ Sobel Performance Summary (%d slices) ============\n\n",
SOBEL_GROUP_SIZE);
printf("Clkctr case 1 : %7.3f ms (%6.2f FPS)\n", sw_avg*1e3, 1.0/sw_avg);
printf("Clkctr case 2 : %7.3f ms (%6.2f FPS)\n\n", hw_avg*1e3, 1.0/hw_avg);
printf("Clkctr case 3 :\n\n");
printf("-----------------------------------------------------------------\n");
printf("Module | Communication [ms] | Compute [ms] | Total [ms] | FPS\n");
printf("-------+--------------------+--------------+------------+--------\n");
for (unsigned int index = 0; index < SOBEL_GROUP_SIZE; ++index) {
const double comm = cumul_sobel_clock_data[index][0]/NUM_ITERATIONS;
const double comp = cumul_sobel_clock_data[index][1]/NUM_ITERATIONS;
const double total = cumul_sobel_clock_data[index][2]/NUM_ITERATIONS;
printf("%6u | %14.3f | %8.3f | %6.3f | %6.2f\n", index, comm*1e3, comp*1e3,
total*1e3, 1.0/total);
}
printf("\n===============================================================\n");
}
Finally, don’t forget to update the method declaration inside controller.h :
void print_results(double sw_time, double hw_time,
double sobel_clock_data[SOBEL_GROUP_SIZE][3]);
7.6. Results#
Running the application with 8 Sobel instances and the newly added Clkctrs results in the following output:
======= Sobel Performance Summary (8 slices, 100 iterations avg) =======
Clkctr case 1 : 7.257 ms (137.80 FPS)
Clkctr case 2 : 7.256 ms (137.81 FPS)
Clkctr case 3 :
-----------------------------------------------------------------
Module | Communication [ms] | Compute [ms] | Total [ms] | FPS
-------+--------------------+--------------+------------+--------
0 | 3.53991 | 2.82436 | 6.96967 | 143.48
1 | 3.52008 | 2.82436 | 6.93906 | 144.11
2 | 3.47944 | 2.82436 | 6.89842 | 144.96
3 | 3.43561 | 2.82436 | 6.85459 | 145.89
4 | 3.55819 | 2.82436 | 6.97717 | 143.32
5 | 3.51995 | 2.82436 | 6.93893 | 144.11
6 | 3.47897 | 2.82436 | 6.89795 | 144.97
7 | 3.43322 | 2.82436 | 6.85220 | 145.94
========================================================================
Experimenting with different number of hardware instances shows that communication takes a growing portion of the execution time with a higher count of hardware instances. This indicates that the DDR accesses become a limiting factor, constraining the achievable acceleration.